
Introduction
With India’s 2019 General Elections around the corner, I thought it’d be a good idea to analyse the election manifestos of its 2 biggest political parties, BJP and Congress. Let’s use text mining to understand what each party promises and prioritizes.
In this part 2, I’ll explore the Economic Growth discussions in both manifestos.
Analysis
Load libraries
rm(list = ls())
library(tidyverse)
library(pdftools)
library(tidylog)
library(hunspell)
library(tidytext)
library(ggplot2)
library(gridExtra)
library(scales)
library(reticulate)
library(widyr)
library(igraph)
library(ggraph)
theme_set(theme_light())
use_condaenv("stanford-nlp")Read cleaned data
bjp_content <- read_csv("../data/indian_election_2019/bjp_manifesto_clean.csv")
congress_content <- read_csv("../data/indian_election_2019/congress_manifesto_clean.csv")Economic Growth
This topic is covered in congress’ manifesto from Pages 9 to 13 of the pdf and in that of bjp’s from pages 13 to 20.
bjp_content %>%
filter(page >=13,
page <= 20) -> bjp_content
congress_content %>%
filter(page >=9,
page <= 13) -> congress_contentMost Popular Words
plot_most_popular_words <- function(df,
min_count = 15,
stop_words_list = stop_words) {
df %>%
unnest_tokens(word, text) %>%
anti_join(stop_words_list) %>%
mutate(word = str_extract(word, "[a-z']+")) %>%
filter(!is.na(word)) %>%
count(word, sort = TRUE) %>%
filter(str_length(word) > 1,
n > min_count) %>%
mutate(word = reorder(word, n)) %>%
ggplot( aes(x=word, y=n)) +
geom_segment( aes(x=word, xend=word, y=0, yend=n), color="skyblue", size=1) +
geom_point( color="blue", size=4, alpha=0.6) +
coord_flip() +
theme(panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") -> p
return(p)
}custom_stop_words <- bind_rows(tibble(word = c("india", "country", "bjp", "congress", "government"),
lexicon = rep("custom", 5)),
stop_words)bjp_content %>%
plot_most_popular_words(min_count = 8,
stop_words_list = custom_stop_words) +
labs(x = "",
y = "Number of Occurences",
title = "Most popular words related to Economy Growth in BJP's Manifesto",
subtitle = "Words occurring more than 8 times",
caption = "Based on election 2019 manifesto from bjp.org") -> p_bjp
congress_content %>%
plot_most_popular_words(min_count = 10,
stop_words_list = custom_stop_words) +
labs(x = "",
y = "Number of Occurences",
title = "Most popular words related to Economy Growth in Congress' Manifesto",
subtitle = "Words occurring more than 10 times",
caption = "Based on election 2019 manifesto from inc.in") -> p_congress
grid.arrange(p_bjp, p_congress, ncol = 2, widths = c(10,10))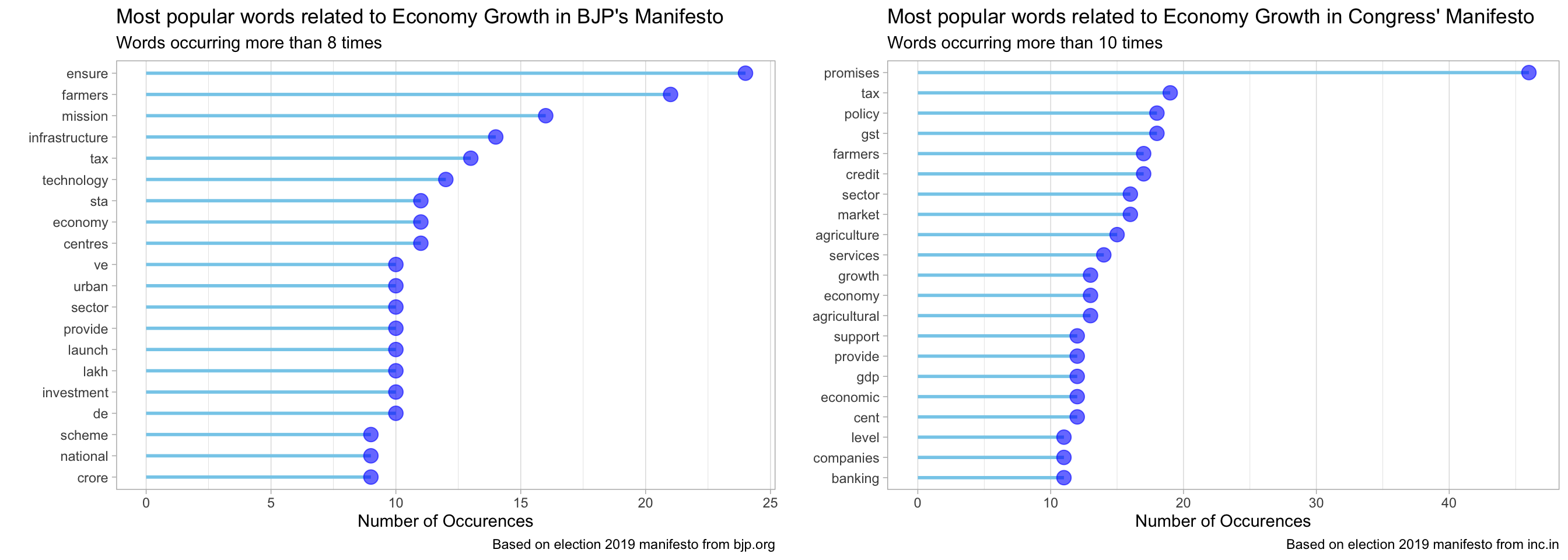
Common correlated words
plot_common_correlated_words <- function(df,
counts_quantile = 0.7,
correlation_threshold = 0.25,
stop_words_list = stop_words) {
set.seed(123)
df %>%
unnest_tokens(word, text) %>%
anti_join(stop_words_list) %>%
add_count(word) %>%
filter(n > stats::quantile(n, counts_quantile)) %>%
pairwise_cor(word, page, sort = TRUE) %>%
filter(correlation > correlation_threshold,
!str_detect(item1, "\\d"),
!str_detect(item2, "\\d")) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void() -> p
return(p)
}bjp_content %>%
plot_common_correlated_words(stop_words_list = custom_stop_words,
counts_quantile = 0.85) +
labs(x = "",
y = "",
title = "Commonly Occurring Correlated Words in BJP's Manifesto",
subtitle = "Per page correlation higher than 0.25",
caption = "Based on election 2019 manifesto from bjp.org") -> p_bjp
congress_content %>%
plot_common_correlated_words(stop_words_list = custom_stop_words,
counts_quantile = 0.85) +
labs(x = "",
y = "",
title = "Commonly Occurring Correlated Words in Congress's Manifesto",
subtitle = "Per page correlation higher than 0.25",
caption = "Based on election 2019 manifesto from inc.in") -> p_congress
grid.arrange(p_bjp, p_congress, ncol = 2, widths = c(12,12))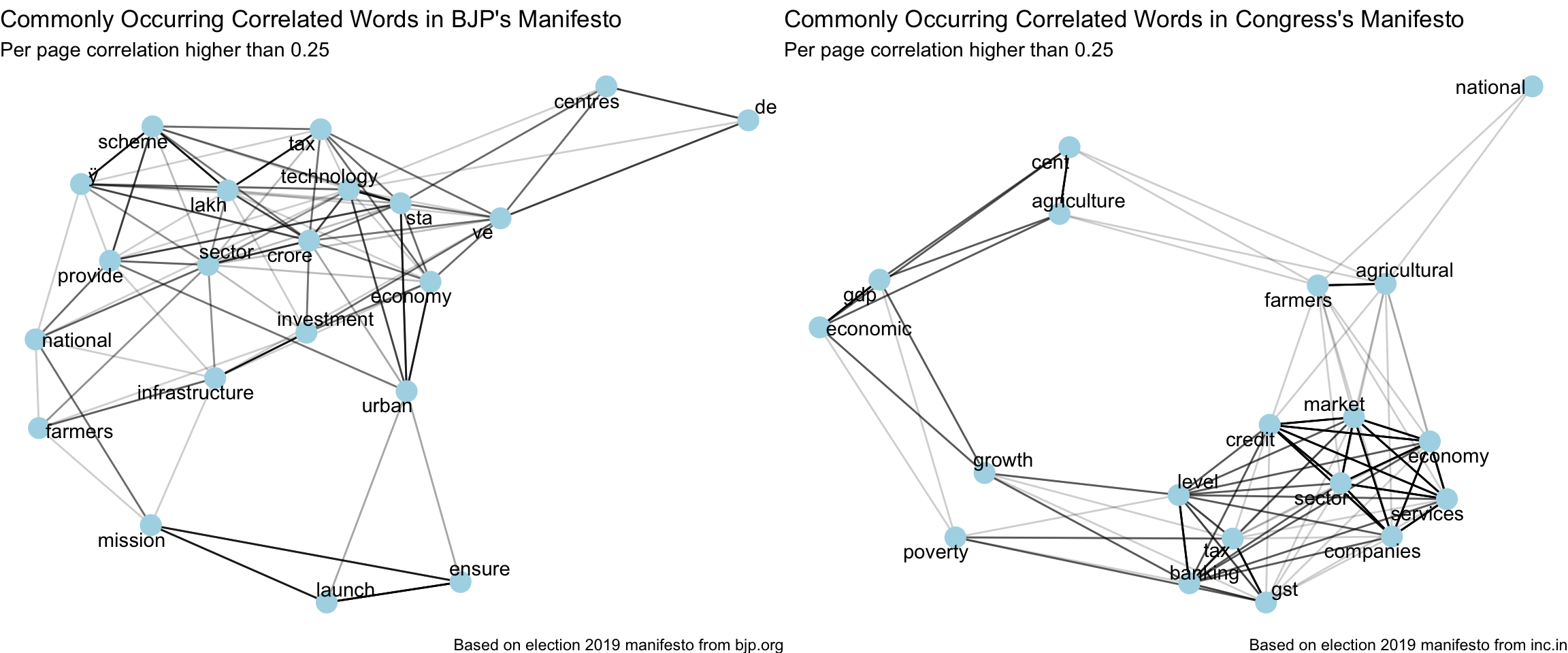
Basic Search Engine
Lets build a cosine-similarity based simple search engine (instead of the basic keyword-based search that comes with the pdf document), in order to make these documents more easily searchable and gain context using most related lines in the manifestos for a given query. Using python’s scikit-learn for this.
from sklearn.feature_extraction.text import TfidfVectorizer, ENGLISH_STOP_WORDS
from sklearn.metrics.pairwise import linear_kernel
stopwords = ENGLISH_STOP_WORDS
vectorizer_bjp = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vector_train_bjp = vectorizer_bjp.fit_transform(r["bjp_content$text"])
vectorizer_congress = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vector_train_congress = vectorizer_congress.fit_transform(r["congress_content$text"])
def get_related_lines(query, party="bjp"):
if (party == "bjp"):
vectorizer = vectorizer_bjp
vector_train = vector_train_bjp
else:
vectorizer = vectorizer_congress
vector_train = vector_train_congress
vector_query = vectorizer.transform([query])
cosine_sim = linear_kernel(vector_query, vector_train).flatten()
return cosine_sim.argsort()[:-10:-1]get_related_lines <- py_to_r(py$get_related_lines)Common Popular Words with both BJP & Congress
As we see from the plot above, one of the most popular words in both BJP and Congress’ manifesto for economy growth is “farmers”. Lets see, what each of them have planned for our farmers. First, BJP.
bjp_content %>%
slice(get_related_lines("farmer", party = "bjp")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 linkages for warehousing of agricultural produce. 13 30
# 2 cooperatives 14 14
# 3 and strengthen them. 14 17
# 4 status sustain the behavioural change. 20 43
# 5 15 15 18
# 6 27 we will promote aquaculture through easy access to credit. 15 13
# 7 28 we will facilitate farming of sea-weed, pearl as well as ornam… 15 14
# 8 shermen. 15 15
# 9 29 we will bring all shermen under the ambit of all welfare progr… 15 16This is the excerpt that we find from page 13, as we dug up based on above results -
Warehouse Network across the Country - We will build an efficient storage and transport mechanism for agricultural produce.
- Our Pradhan Mantri Krishi SAMPADA Yojana highlights our focus on warehousing as a means of increasing farmers’ income. To further expand the warehousing infrastructure in the country, we will establish a National Warehousing Grid along National Highways to ensure necessary logistical linkages for warehousing of agricultural produce.
- To enable the farmer to store the agri-produce near his village and sell at a remunerative price at an appropriate time, we will roll out a new Village Storage Scheme of agri-produce. We will provide farmers with loans at cheaper rates on the basis of storage receipt of the agri-produce.
Now, Congress.
congress_content %>%
slice(get_related_lines("farmer", party = "congress")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 and apex co-operative banks were denied the right to convert thei… 9 8
# 2 criminal proceedings to be instituted against 11. congre… 9 26
# 3 05. congress promises to establish a permanent ad… 9 31
# 4 02. we will not stop with just providing “karz maafi” re… 9 19
# 5 to examine and advise the government on how to import… 9 35
# 6 co-operative credit to the farmer; the terms of trade moved decis… 9 9
# 7 economy, creation of wealth, sustainable development, reduction o… 10 50
# 8 congress economic philosophy is based on embracing the idea of an… 10 49
# 9 animal spirits of our entrepreneurs. will be su… 10 48One of the full excerpts from page 9 related to above results -
Congress promises to establish a permanent National Commission on Agricultural Devel- opment and Planning consisting of farmers, agricultural scientists and agricultural economists to examine and advise the government on how to make agriculture viable, competitive and remuner- ative. The recommendations of the Commission shall be ordinarily binding on the government. The Commission will subsume the existing Commission for Agricultural Costs and Prices and recommend appropriate minimum support prices.
Unique popular words with BJP & Congress
One of the popular words that seems curious from BJP’s manifesto is “technology”. Let’s see what BJP has planned for the use of technology for economic growth.
bjp_content %>%
slice(get_related_lines("technology", party = "bjp")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 return to the farmers. 14 22
# 2 typing of msmes. they will expose msmes to a i cial intelligence,… 18 32
# 3 22 we will ensure faster customs clearance of international cargo… 19 41
# 4 19 we will enable development of young agri-scientists to take ad… 14 28
# 5 ve years. this includes massive budgetary allocation for railways… 20 12
# 6 a major step in expanding of ‘technology centres’ and we would ac… 18 30
# 7 aim to take this gure to rs.1,00,000 crore by 2024. 18 28
# 8 rental/custom hiring basis. 14 25
# 9 10 technology access and upgradation are key elements in the msme… 18 29An excerpt from BJP’s manifesto about use of technology as identified from above -
We will enable development of young agri-scientists to take advantage of Artificial Intelligence, Machine Learning, Blockchain Technology, Big Data Analytics etc. for more predictive and profitable precision agriculture.
Suprising to see mention of plans for usage of Machine Learning and Blockchain in BJP’s manifesto.
Now, one of the popular words that seems curious from Congress’ manifesto is “gst”.
congress_content %>%
slice(get_related_lines("gst", party = "congress")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 15. msmes were badly hit by demonetisation and 11 45
# 2 fessionals. its minutes will be put in the public … 12 49
# 3 food grains, lifesaving drugs, vaccines, etc.) and 12 54
# 4 07. all goods and services that are exported will 12 59
# 5 growth, new businesses and employment. the her busine… 12 39
# 6 and will be served by a permanent secretariat of … 12 45
# 7 01. congress promises to review and replace the 08. congre… 12 24
# 8 2.0 will be only in cases of criminal conspiracy or … 12 61
# 9 petroleum products, tobacco and liquor will be 12 43MSMEs were badly hit by demonetisation and a flawed GST. Congress promises to devise a rehabilitation plan for MSMEs that were severely affected and help them revive and grow.
Congress is planning for a rehabilitation program for the Micro Small & Medium Enterprises. They also have a plan to redefine MSMEs -
MSMEs account for 90 per cent of all employment outside agriculture. The definition of MSMEs based on capital employed is biased against labour. Congress will link the definition of MSME to employment. A business employing 10 persons or less will be ‘micro;’ between 11 and 100 will be ‘small;’ and between 101 and 500 will be ‘medium.’
With all the above analysis, we have developed some idea about the economic growth plans of the 2 parties. In the next post, I’ll do a similar analysis for employment and opportunites proposals of them.
Stay Tuned!
References
- Part 1 - Data Collection and Cleaning
- Part 3 - Employment and Opportunities
- For all the parts go to Project Summary Page - India General Elections 2019 Analysis