
Introduction
With India’s 2019 General Elections around the corner, I thought it’d be a good idea to analyse the election manifestos of its 2 biggest political parties, BJP and Congress. Let’s use text mining to understand what each party promises and prioritizes.
In this part 7, I’ll explore the Education, Health Care and other miscellaneous discussions in both manifestos.
Analysis
Load libraries
rm(list = ls())
library(tidyverse)
library(pdftools)
library(tidylog)
library(hunspell)
library(tidytext)
library(ggplot2)
library(gridExtra)
library(scales)
library(reticulate)
library(widyr)
library(igraph)
library(ggraph)
theme_set(theme_light())
use_condaenv("stanford-nlp")Read cleaned data
bjp_content <- read_csv("../data/indian_election_2019/bjp_manifesto_clean.csv")
congress_content <- read_csv("../data/indian_election_2019/congress_manifesto_clean.csv")Education, Health Care and Miscellaneous
This topic is covered congress’ manifesto from Pages 24 to 27 of the pdf and in that of bjp’s from pages 23 and 29 to 30 and 36 to 37.
bjp_content %>%
filter(between(page, 23, 23) | between(page, 29, 30) | between(page, 36, 37)) -> bjp_content
congress_content %>%
filter(between(page, 24, 27)) -> congress_contentMost Popular Words
plot_most_popular_words <- function(df,
min_count = 15,
stop_words_list = stop_words) {
df %>%
unnest_tokens(word, text) %>%
anti_join(stop_words_list) %>%
mutate(word = str_extract(word, "[a-z']+")) %>%
filter(!is.na(word)) %>%
count(word, sort = TRUE) %>%
filter(str_length(word) > 1,
n > min_count) %>%
mutate(word = reorder(word, n)) %>%
ggplot( aes(x=word, y=n)) +
geom_segment( aes(x=word, xend=word, y=0, yend=n), color="skyblue", size=1) +
geom_point( color="blue", size=4, alpha=0.6) +
coord_flip() +
theme(panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position="none") -> p
return(p)
}custom_stop_words <- bind_rows(tibble(word = c("india", "country", "bjp", "congress", "government"),
lexicon = rep("custom", 5)),
stop_words)bjp_content %>%
plot_most_popular_words(min_count = 7,
stop_words_list = custom_stop_words) +
labs(x = "",
y = "Number of Occurences",
title = "Most popular words related to Education, Healthcare & Misc in BJP's Manifesto",
subtitle = "Words occurring more than 7 times",
caption = "Based on election 2019 manifesto from bjp.org") -> p_bjp
congress_content %>%
plot_most_popular_words(min_count = 12,
stop_words_list = custom_stop_words) +
labs(x = "",
y = "Number of Occurences",
title = "Most popular words related to Education, Healthcare & Misc in Congress' Manifesto",
subtitle = "Words occurring more than 12 times",
caption = "Based on election 2019 manifesto from inc.in") -> p_congress
grid.arrange(p_bjp, p_congress, ncol = 2, widths = c(10,10))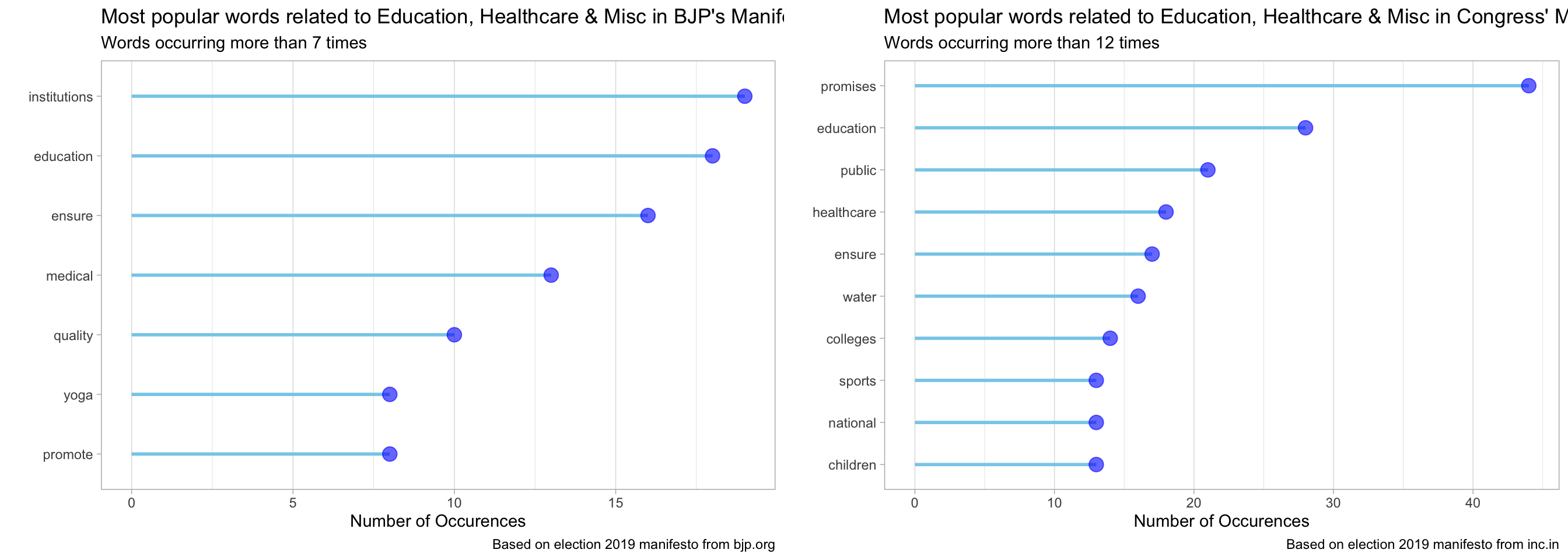
Common correlated words
plot_common_correlated_words <- function(df,
counts_quantile = 0.7,
correlation_threshold = 0.25,
stop_words_list = stop_words) {
set.seed(123)
df %>%
unnest_tokens(word, text) %>%
anti_join(stop_words_list) %>%
add_count(word) %>%
filter(n > stats::quantile(n, counts_quantile)) %>%
pairwise_cor(word, page, sort = TRUE) %>%
filter(correlation > correlation_threshold,
!str_detect(item1, "\\d"),
!str_detect(item2, "\\d")) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void() -> p
return(p)
}bjp_content %>%
plot_common_correlated_words(stop_words_list = custom_stop_words,
counts_quantile = 0.85) +
labs(x = "",
y = "",
title = "Commonly Occurring Correlated Words in BJP's Manifesto",
subtitle = "Per page correlation higher than 0.25",
caption = "Based on election 2019 manifesto from bjp.org") -> p_bjp
congress_content %>%
plot_common_correlated_words(stop_words_list = custom_stop_words,
counts_quantile = 0.85) +
labs(x = "",
y = "",
title = "Commonly Occurring Correlated Words in Congress's Manifesto",
subtitle = "Per page correlation higher than 0.25",
caption = "Based on election 2019 manifesto from inc.in") -> p_congress
grid.arrange(p_bjp, p_congress, ncol = 2, widths = c(12,12))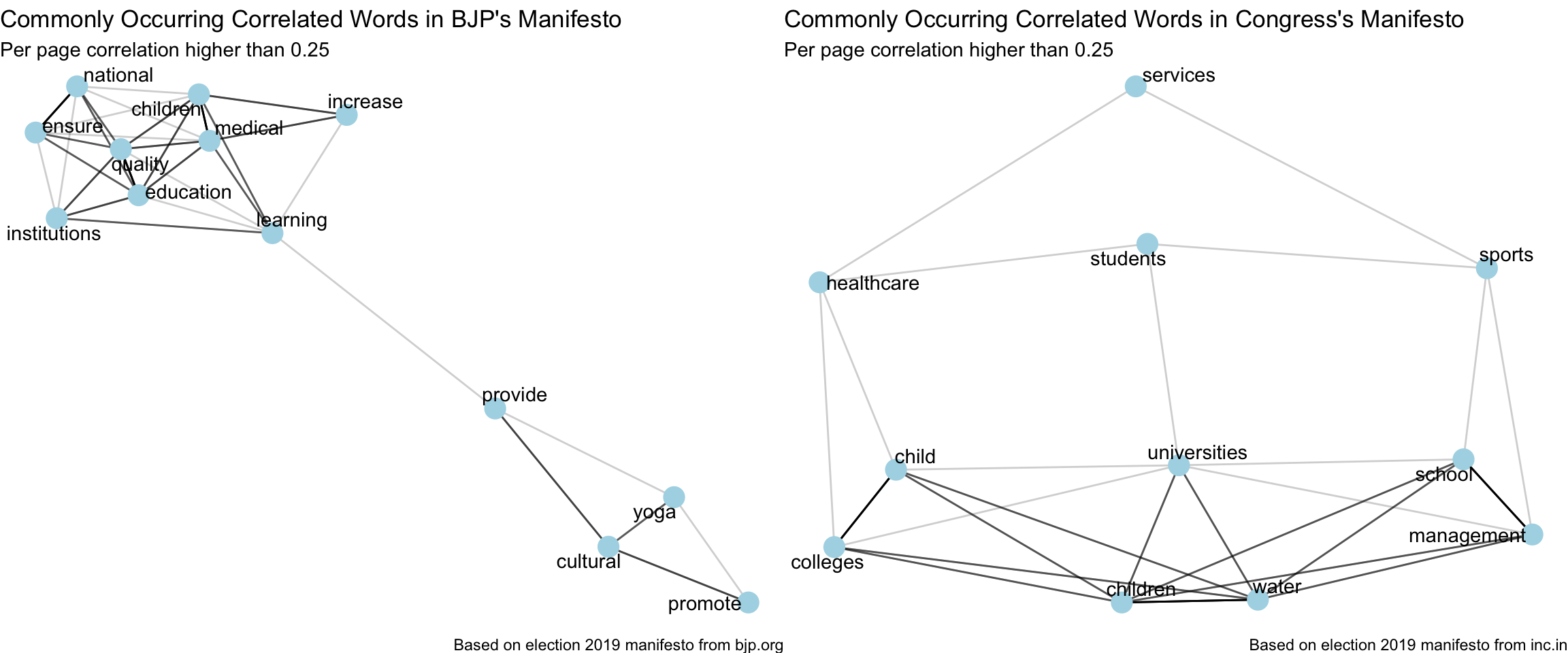
Basic Search Engine
Lets build a cosine-similarity based simple search engine (instead of the basic keyword-based search that comes with the pdf document), in order to make these documents more easily searchable and gain context using most related lines in the manifestos for a given query. Using python’s scikit-learn for this.
from sklearn.feature_extraction.text import TfidfVectorizer, ENGLISH_STOP_WORDS
from sklearn.metrics.pairwise import linear_kernel
stopwords = ENGLISH_STOP_WORDS
vectorizer_bjp = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vector_train_bjp = vectorizer_bjp.fit_transform(r["bjp_content$text"])
vectorizer_congress = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vector_train_congress = vectorizer_congress.fit_transform(r["congress_content$text"])
def get_related_lines(query, party="bjp"):
if (party == "bjp"):
vectorizer = vectorizer_bjp
vector_train = vector_train_bjp
else:
vectorizer = vectorizer_congress
vector_train = vector_train_congress
vector_query = vectorizer.transform([query])
cosine_sim = linear_kernel(vector_query, vector_train).flatten()
return cosine_sim.argsort()[:-10:-1]get_related_lines <- py_to_r(py$get_related_lines)Common Popular Words with both BJP & Congress
As we see from the plot above, one of the most popular words in both BJP and Congress’ manifesto is “children”. Lets see, what each of them have planned for the children of our country. First, BJP.
bjp_content %>%
slice(get_related_lines("children", party = "bjp")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 facilitate them to unleash their talent. for this, we will initia… 29 12
# 2 training and capacity building as a key factor in achieving these… 29 10
# 3 per year to 6% per year. continuing this pace, we will ensure ful… 23 37
# 4 04 we are commi ed to using technology in classrooms and in impa … 29 20
# 5 infrastructure and capacity in all anganwadis. 23 34
# 6 learning. we have already identi ed learning outcomes for various… 29 8
# 7 code, drawing upon the best traditions and harmonizing them with … 37 10
# 8 optimally bene t from the education system. 29 5
# 9 ve years will be to ensure that children achieve these learning o… 29 9This is the excerpt that we find from page 29, as we dug up based on above results -
We consider it our duty to provide a conducive environment for talented children in our country to facilitate them to unleash their talent. For this, we will initiate a ‘Prime Minister Innovative Learning Program’ to bring together such children for a certain period in a year in one place from all over the country and provide them with facilities and resources for them to excel. This would instill a culture of lateral thinking and innovation among them.
Now, Congress.
congress_content %>%
slice(get_related_lines("children", party = "congress")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 49 environment and climate change 26 19
# 2 be transferred to the state list in the seventh of … 25 8
# 3 promises that state and central governments shall be responsible … 25 3
# 4 include a crèche to provide day care to small 06. crime… 26 28
# 5 03. we are deeply concerned about the quality of ed- … 25 17
# 6 them through mobile fair price shops. and t… 26 6
# 7 45 education 25 1
# 8 ucation and poor learning outcomes as reported 10. mos… 25 18
# 9 system of education revolves. teacher training 11. con… 25 23One of the excerpts from page 25 related to above results -
Congress promises that school education from Class I to Class XII in public schools shall be compulsory and free. Suitable amendments will be made in the Right to Education Act, 2009. We will end the practice of charging special fees for different purposes in public schools.
Unique popular words with BJP & Congress
One of the popular words that seems curious from BJP’s manifesto is “yoga”.
bjp_content %>%
slice(get_related_lines("yoga", party = "bjp")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 spiritual rejuvenation across the globe and will continue to work… 36 34
# 2 08 we will fu her continue our e o s to promote yoga globally as … 36 32
# 3 endeavour to secure constitutional protection on issues related t… 36 30
# 4 international yoga day. we will promote yoga as a vital method to… 36 33
# 5 promoting yoga globally 36 31
# 6 code, drawing upon the best traditions and harmonizing them with … 37 10
# 7 02 we consider it our duty to provide a conducive environment for… 29 11
# 8 ve years will be to ensure that children achieve these learning o… 29 9
# 9 learning. we have already identi ed learning outcomes for various… 29 8An excerpt from BJP’s manifesto about use of yoga as identified from above -
We will further continue our efforts to promote Yoga globally as the world celebrates 21st June as the International Yoga Day. We will promote Yoga as a vital method to achieve physical wellness and spiritual rejuvenation across the globe and will continue to work towards training of Yoga practitioners. We will undertake a rapid expansion of Yoga health hubs, Yoga tourism and research in Yoga.
Now, one of the popular words that seems curious from Congress’ manifesto is “sports”.
congress_content %>%
slice(get_related_lines("sports", party = "congress")) %>%
select(text, page, line)# # A tibble: 9 x 3
# text page line
# <chr> <dbl> <dbl>
# 1 that will place india at the forefront of … 27 25
# 2 50 climate resilience and disaster management … 27 36
# 3 for forest conservation and afforestation. incenti… 27 22
# 4 climate change. … 27 42
# 5 02. congress will take suitable measures to ensure … 27 33
# 6 congress affirms its belief that india has the potential to becom… 27 24
# 7 disaster management act, 2005 and incorporate inf… 27 45
# 8 07. we will ensure that there is at least 1 community 27 39
# 9 01. congress promises to re-visit the national 05.… 27 44Congress will take suitable measures to ensure that the Constitution of each sports body is in accordance with certain norms and principles, that elections are held according to them, and that there is adequate representation in each sports body for active players, former players and women.
With all the above analysis, we have developed some idea about the Education, Healthcare and other miscellaneous plans of the 2 parties.
With this I conclude my analysis of the manifestos of BJP and Congress for 2019 general elections. I highly encourage all my readers to make their choice carefully in these pivotal elections and even though these analyses give you a high level idea about each party, maybe try and go through the entire manifestos to make a much informed decision about your choice and ensure accountability from our governments.
Let’s hope for and build a better India. All the best!
References
- Part 6 - National Security
- For all the parts go to Project Summary Page - India General Elections 2019 Analysis